|
根据运行的环境,操作系统可以分为桌面操作系统,手机操作系统,服务器操作系统,嵌入式操作系统等。
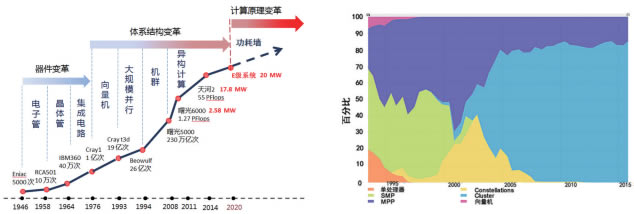
关于超级计算机的现状和我国的发展计划. 在Ppt文件中,爱文共享的信息具有丰富的相关文档,每天都有成千上万的行业名人共享最新信息. 超级计算机的现状和中国的发展计划. 接下来,我将代表国家超级计算机天津中心,主要介绍“天河一号”及其在融合领域的合作进展. 该中心和天河一号介绍了未来国家超级计算天津中心的关键研发方向和资源更新计划**超级计算机的现状和国内发展计划HPC发展战略和情况第一部分**天河No.2万亿次从万亿次到万亿次两年前,性能每年提高了两倍,第一台商用巨型机器问世了. 超级计算机的状况和发展计划PFlops petaflops每年的时间间隔超级计算机的性能提高了1亿倍,即平均每年性能提高了近1000万倍. 这个速度非常惊人. 那么,我们如何认为超级计算机可以实现如此快速的性能提升呢? ****超级计算机的状态和发展计划改善超级计算机性能的三驾马车频率,指令级并行度,并行度并行度足够宽(成千上万个节点),并且深度足够深(内核间,异构,SIMD,指令级))多年来提高了系统计算性能的三驾马车: 主频率,指令级并行性和并行性. 当前,系统性能的提高主要取决于并行度: 足够宽(成千上万个节点)和足够深(内核间,异构,SIMD,指令级))****超级计算机是并行化的基础. 国家全面的科技创新能力. 世界上所有主要国家都在大力发展超级计算机. 近年来,中国一直在大力发展超级计算机. 超级计算机的现状和发展计划是由于认识到超级计算机是全面的. 因此大力发展对科学技术创新能力的基础支持.
****天河超级计算机的发展历史得到了小平的认可. 国防科技大学批准小平开始“银河”的开发. 从那时起,中国发展超级计算机的艰辛而辉煌的历史. 经批准,NUDT从此开始开发“银河系”,从此开始了中国超级计算机研究的艰巨而辉煌的历史. GalaxyMflops,Galaxy Gflops,天河1号Pflops,天河2号Pflops,秘书长****高性能计算机超级计算机RD建立了合作关系研发机制,集中力量,突破核心关键技术,开发Eflops超级计算系统(Pflops),并建立HPC应用程序支持高性能计算应用程序适应不同行业的国家高性能计算应用程序软件中心. 部署具有行业功能的主要应用软件系统. 开发基于容量的行业主要应用数值模拟软件平台. 部署容量型通用升级应用程序. 部署国家超级计算中心来培养,吸引和吸引稳定具有独立应用软件系统的一组用户. HPC环境建设构建具有世界级资源能力和服务水平的国家高性能计算环境,以支持国家创新和发展. 科学技术部的高性能计算计划: MOSTprojectson HPC: 科学技术部也在不断增加对高性能计算的投资中,制定了年度发展计划. 软硬件研发与应用: 拟建立按行业和应用领域划分的计算平台环境建设: 服务应用水平****国家超级计算机天津中心和天河第一导论NSCCTJTianheA第二部分中国的应用范围目前投入运行的国家超级计算中心最广泛,最全面的支持能力达到了天河第一超级计算机站的万亿倍. 通用云计算系统容量超过PB. 大容量存储系统. 多部门行业软件. 完善的网络基础架构. 基础设施,例如机房,电源和冷却系统. 主要业务是高性能计算,云计算和大数据服务. 目前服务的政府,企业和科研机构的用户数量已超过一个. NSCCTJ中国规模最大,功能最强大的国家超级计算中心天河目前已投入运行. 1台超级计算机的大容量存储系统容量超过PB. 多部门行业软件非常完美. 网络基础设施是完美的. 机房,电源,冷却系统和其他基础设施都很齐全. *国家发改委“大数据技术与应用”国家和地方联合工程实验室,工业和信息化部产业云试点单位,科技部示范国际合作基地国家博士后研究站由多家企业和研究机构共同建立的NSCCTJ *联合实验室*计算机技术创新广泛的应用效果天河一号是基于上述经验的积累而建立的. 天河一号的认可主要是由于两个原因: *国际学术评价来自国际学术界的评论CPU GPU异构融合体系结构CPU GPU异构体系结构位多核多线程自主CPUbits多核与多线程CPU自主高速互连通信技术自主研发的高速互连通信技术三项技术创新三项技术创新是比带宽主流更高的单向通信技术Infiniband QDR **石油勘探石油勘探生物医学生物医学航空航天设计受控核聚变核聚变气象预报天气预测高性能计算的主要应用领域HPC的主要应用领域设计设计高端设备制造高端设备制造土木工程设计分析BIM金融工程重要基础科学超级计算研究: 增强国家创新能力,加快战略新兴产业的发展提高国家创新能力,加快中国战略的发展**行业专家和用户行业最全面的服务能力最稳定的服务质量优质计算服务的时间计算应用程序: >一万台机器每天运行的任务数: >存储的数据规模: >迄今为止PB服务的运行状态(年,月,日和日)天津超级计算机中心的运行状态**天津超级计算机中心运行情况“天河一号”系统稳定的运行服务支持的项目超过国家重大科研项目,国家自然科学基金项目,项目和其他重大项目(工业和信息化部,发改委,中国石油,中海油等),更多一个国际和地区性项目,不仅是服务,而且该国大多数省(包括香港)的服务用户已超过**融合领导者. 领域研究合作单位: 北京大学,中国科学技术大学,浙江大学, nvidia Tokamak“循环等离子代码” GTC程序GPU开发和优化模拟规模: ?,内核每秒模拟超过1亿个电子. 再次感谢我们的合作部门.
****融合技术开发及相关合作实际操作GTC程序移植到“天河一号”程序部署热点分析Pushe: 获取网格点的现场数据并根据力更新电子位置Shifte: 高度串行计算MPI操作实际上已处理. . . 电子模块占用整个程序的运行时间. 对该模块热点的进一步分析表明,pushe和shifte这两个部分花费的时间最多. 因此,我们将这两部分放入GPU中以执行加速. 同时,我们还优化了GPU中的操作. PUSHEtakesaboutofthetotaltimeSHIFTEtakesaboutofthetotaltimePusheroutinesmainlydotwothings: oneisforgatheringelectronicorelectromagneticfieldsatgridpoint(toeveryelectron'spositions)Theotherisforupdatingelectrons'positionsbasedonthegatheredfieldsThefieldgatheringloopishighlyparallel: thecalculationsofeveryparticlearecompletelyindependentSHIFTEcontainsbothcomputationandMPIpartThecomputationpartcontainstwomajorsteps: FigureoutwhichparticlesneedtobetransferredoutsideofthecurrentMPIprocessandthencopyingoutgoingparticlestoseparatesendbuffersFillinthe “洞” intheparticlearrayleftaftermovingoutsomeparticlessothatvalidparticlesofoneMPIprocessarealwaysstoredcontinuouslyinmemoryThetwocomputationalpartsarehighlysequentialsotheyareactuallynotveryexpensiveonCPUSequentialreason: onlyafterallthepreviousoutgoingparticlesareprocessed,onecanknowwheretoputthenextoutgoingparticleHowever,portingSHIFTEtoGPUisimportantfortheoverallperformanceoftheGPUcodeIfSHIFTEstaysonCPU,oneneedstotransferalltheparticl在此情况下,如果不知道要丢弃哪些粒子,则在这种情况下,数据传输将是相当大的开销,如果可以将GPU上的流出粒子识别出来,则几乎没有需要将粒子转移回CPU,这通常是较小的分数. ****用于融合技术开发和相关合作程序的特定优化策略三维访问阵列的内存访问优化(用于pushe)纹理绑定合并阵列提高缓存命中率CPUGPU数据传输优化(用于pushe)临时阵列直接GPU寄存器在GPU中分配,以不变地存储部分阵列. 仅在首次调用内核时,才将数组传递给GPU算法优化(用于shifte). 对于分层并行压缩: 串行代码通过分层扫描方法与内核并发执行. 通过在GPU中使用多个流,可以通过优化pushe和shifte子函数分别实现对GPU性能的提高(从总性能到SHIFTTEgets?xspeedup)到GPU传输时间减少到pushekerneltimePUSHEgets?xspeedup的并发执行,从而分别实现双加速和双加速. ****融合技术的发展和相关合作以一个节点为例高性能计算机发展历程,说明了GPU对电子模块Profile的加速和MPI进程打开MP线程运行的CPU版本和GPU版本的加速. 总的时域铁移位泵送电子装置. 优化的pushe和shifte子功能分别实现了双倍和双倍加速.
****融合技术开发和相关合作WeakScalingTestGTC的整体性能提高了?倍,并且程序具有良好的可伸缩性. 在弱缩放下,左图: 纵坐标是每秒处理的电子数. 为了说明GTC程序的可伸缩性,测试节点的数量从总大小的节点到每种类型的节点测试不等. 红色曲线用于使用一个CPU. 蓝色曲线用于使用两个CPU. 上方的两条曲线用于使用GPU. 较低的测试结果仅适用于CPU. 可以看出,在天河1号上使用GPU进行加速可以实现双倍加速. 当使用的节点数大于弱缩放条件下的加速比时,该比例基本上保持不变,表明GTC程序具有良好的可缩放性. 加速比降低的原因: 当使用的节点数增加时,MPI通信消耗的时间比例逐渐增加. cpu程序的可伸缩性较弱的问题导致加速比降低. ****融合技术开发及相关合作单位: 中科院等离子体研究所天河边界湍流模拟程序BOUT的可扩展性测试和分析: 成功将BOUT部署到天河系统并进行了多套可伸缩性测试. 在图中与国家能源研究科学计算中心NERSC的Edison系统进行测试比较. 图中的耗时统计信息是耗时的测试步骤总数. 该过程是、、、、和组. 融合技术开发和相关合作测试环境的比较: 计算节点: NERSCEdison: 单核IntelIvyBridge处理器GHz天河之一: NEERSCEdison: CrayArieswithDragonflytopologywithTBsglobalbandwidth天河一: 独立的高速互连MPI实现: NERSCEdison: 基于GCC(CrayInc),Craympich Tianhe之一: 基于GCC编译器,mpi ****融合技术的发展以及由openmpi编译产生的相关合作. 爱迪生和天河一号的测试比较了天河openmpi下的CALC,以保持更好的缩放比例. 求解器的缩放比例最差. 当进程数大于在天河上使用openmpi编译的bout时,缩放不佳的原因是,求解器模块中PVODE求解器消耗的时间随着进程数的增加而增加. 导致耗时异常的代码段正在针对求解器模块进行进一步分析. 根据计算步骤计算图中的各个链接和总经过时间. Tianheopenmpi代表使用GCC在Tianhe系统上编译openmpi,使用openmpi编译bout,但依靠库与Intel一起编译. 在天河上使用mpich编译器测试发现,求解器链接中耗时的增长更加不寻常. ****着眼于未来国家超级计算机天津中心的研发方向和资源更新计划. 第三部分大数据融合技术和超级计算协作创新. 加大研发力度. ***美国国家研究委员会的图灵奖获得者JimGray在计算机科学与电信委员会(NRCCSTB)的演讲报告中,提出了科学研究的“第四范式”的第一个范式: 实验范式科学研究主要根据观察和实验来描述自然现象. 第二范式: 理论科学研究的范式第三次理论推导和分析研究的范式主要基于建模和归纳法: 计算科学研究的范式主要基于复杂现象的模拟. 计算科学研究的第四个范式: 数据科学研究的范式基于数据检查. 实验和模拟数据密集型计算处理研究高性能计算,大数据和云计算融合技术FusionTechofBigDataandHPC高性能计算机发展历程,CCatNSCCTJ数据变得越来越重要和更有价值***天津超级计算中心的运营转向数据密集型计算必须强调数据与计算的耦合. 数据在存储时在本地计算. 在计算时,还尽可能使用数据的局部特征.
|
温馨提示:喜欢本站的话,请收藏一下本站!
本站发布的Win7纯净版系统、Win10纯净版和XP纯净版系统仅为个人学习测试使用,请在下载后24小时内删除,不得用于任何商业用途,否则后果自负,请支持购买微软正版软件!
本站所有资源全部来自于网络资源,如侵犯到您的权益,请及时通知我们(),我们会及时处理.
Copyright © 2018-2020 萝卜系统 手机站 关于本站