|
根据运行的环境,操作系统可以分为桌面操作系统,手机操作系统,服务器操作系统,嵌入式操作系统等。
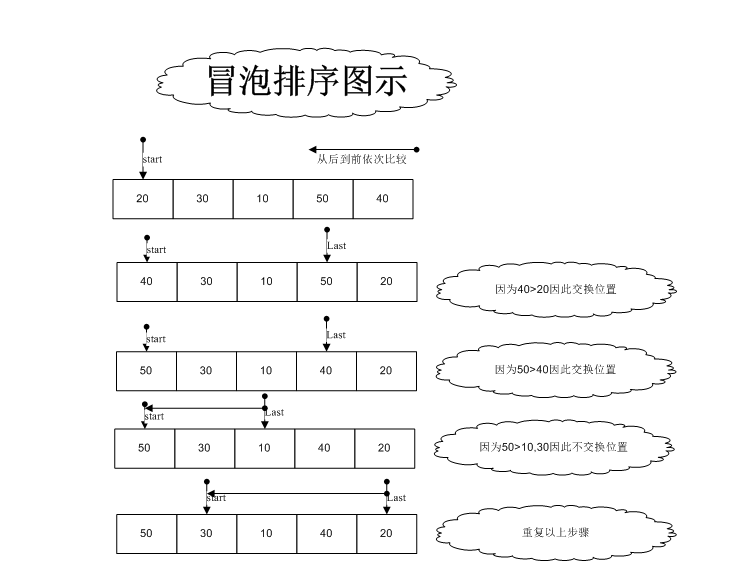
我在前两个博客中详细介绍了“经典算法学习单链接列表(无前导节点)以实现冒泡排序”“经典算法学习单链接列表以实现冒泡排序(领先节点)”链表与主导节点和非主导节点实现泡沫排序,让我们对单链列表和泡沫排序有一个合理的了解. 今天,我们将使用没有前导节点的非循环双链表来实现气泡排序. 在处理过程中,这种气泡比前两种更简单,更有效. 代码已上传到. 核心代码如下: //冒泡排序
Node *BubbleSort(Node *pNode){
int count = sizeList(pNode);
Node *pMove;
pMove = pNode;
//遍历次数为count-1
while (count > 1) {
while (pMove->next != NULL) {
if (pMove->element > pMove->next->element) {
int temp;
//这里的数据交换比单链表简单
temp = pMove->element;
pMove->element = pMove->next->element;
pMove->next->element = temp;
}
pMove = pMove->next;
}
count--;
//再次回到链表头部
pMove = pNode;
}
printf("%s函数执行,冒泡排序完成\n",__FUNCTION__);
return pNode;
}
时间: 03-03 标签:
-> C实现了头插值法和尾插值法来构造一个无头循环链表(无头节点) 在实际使用中,双链表比单链表更加方便和灵活. 对于不带前导节点的无环双链表的基本操作,我用
经典算法学习链接列表以实现冒泡排序 在以前的博客<经典算法学习-气泡排序>中,我只是实现了将数组用于气泡排序的实现. 在此博客中,我们将实现如何使用链接列表进行排序,实际上,总体思路是相同的. 示例代码已上传到: . 该算法描述如下: (1)比较相邻数据前后的两个数据,如果前一个数据大于后一个数据,则交换两个数据: (2)以这种方式将数组的第0个数据转换为N-遍历1个数据后c语言单链表冒泡排序,最大的数据到达最后一个位置,即下标N-1的位置(下沉).
JavaScript经典算法学习1: 辅助类生成随机数组 辅助类是几种经典排序算法的学习部分,为了促进不同算法的统一测试,创建了一个新的辅助类,主要功能是: 生成指定长度的随机数组,提供一个打印输出数组,交换两个元素,等等. 代码如下: function ArraySortUtility(numOfElements){this.dataArr = []; this.pos = 0; this.numOfElements = numOfElements; this.insert =插入; this.toString = toString; this.cle 经典算法学习气泡排序 冒泡排序是我们学习的第一个排序算法. 它应该被认为是最简单的. 最常用的排序算法. 无论如何. 学习它是不可避免的. 今天,我们将使用C语言实现该算法. 演示示例代码已上传至: 算法说明如下: (1)比较相邻前后的两个数据. 假定先前的数据大于后面的数据,则交换两个数据: (2)这是第一个. 从0数据到N-1数据的遍历一次. 最大的数据将到达最后一个位置,该位置是索引为N-1的位置(下沉). (3) 用于经典算法学习的贪婪算法 贪婪算法也用于解决优化问题. 与动态规划相比,使用贪婪算法更容易解决许多问题,但使用贪婪算法并不能解决所有优化问题. 贪婪算法是每个决策点在当时做出最佳选择. 贪心算法的设计步骤: 1.将优化问题转换为: 在对其进行选择之后,仅需要解决一种形式(动态规划将剩下许多问题需要解决)2.证明贪婪选择后做出来后,始终有一个针对原始问题的最佳解决方案,也就是说,贪心算法始终是安全的. 3.在做出贪婪选择的证明之后,其余子问题满足以下性质: 最优解可以与贪婪选择结合以获得原始问题的最优解,从而最大程度地解决 通过排序算法学习的简单排序(气泡排序,简单选择排序,直接插入排序) 一个. 气泡排序气泡排序是最基本的算法,复杂度为O(N ^ 2),其基本思想是: 从最低端的数据开始,然后相互比较. 然后交换. 代码如下: / *最基本的冒泡排序* / void BubbleSort1(int n,int * array)/ * little> big * /(int i,j; for(i = 0; i
经典算法学习-仅出现一次的第一个字符 这也是《健治要约》中非常经典的面试问题. 标题描述为: 查找字符串中仅出现一次的第一个字符. 如果输入“ abaccdeff”,则输出“ b”. 一开始,每个人都会认为最简单的方法是在访问每个字符后比较它们,如果未找到相同的元素,则该元素是仅出现一次的第一个字符. 复杂度为O(n ^ 2). 显然这个效率不高. 这个问题的总体方向是一个问题搜索算法. 常见的搜索算法是顺序搜索,二进制搜索和哈希搜索. 更适合此问题. 这是一个哈希搜索. 首先,我们可以建立一个256长度的数组 经典算法学习-打印两个链表的第一个公共节点 查找链表的公共节点是经典的算法问题,这并不困难. 我们需要知道的是,一旦两个链表都有一个公共节点,那么两个链表的形状就是“ Y”类型,也就是说,该公共节点之后的所有节点都是相同的. 如下: 实际上,只要您看一下这张图片,实现就非常简单. 首先,我们分别遍历两个链表,并分别获得它们的长度L1,L2. . 然后在寻找公共节点时,首先走| L1-L2 |. 在长链表中,将两个链表同时向后遍历,判断每一步后节点是否相同. 如果相同,则找到第一个公共节点. 完整的代码已上传到 经典算法可在数组中快速找到两个数字并将它们加起来达到一定值 此算法的描述如下: 快速找到数组中的两个数字,并使这两个数字的和等于给定值. 目前,我假设数组都是不相等的整数. 这个问题是我在面试中问的. 由于种种原因,我没有回答c语言单链表冒泡排序,这很尴尬. 其实,这个问题很简单,我们用一种比较巧妙的方法来实现. 注意不要使用两层循环的元素遍历. 示例代码已上传到: . 该算法的描述如下: (0)首先对原始数组进行排序以使其成为增量数组: (1)对数组头i [0]和数组尾j [n-1]进行排序 |
温馨提示:喜欢本站的话,请收藏一下本站!
本站发布的Win7纯净版系统、Win10纯净版和XP纯净版系统仅为个人学习测试使用,请在下载后24小时内删除,不得用于任何商业用途,否则后果自负,请支持购买微软正版软件!
本站所有资源全部来自于网络资源,如侵犯到您的权益,请及时通知我们(),我们会及时处理.
Copyright © 2018-2020 萝卜系统 手机站 关于本站