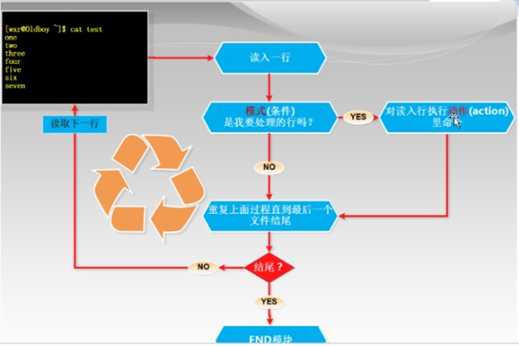
|
根据运行的环境,操作系统可以分为桌面操作系统,手机操作系统,服务器操作系统,嵌入式操作系统等。
-W帮助或--help,-W使用情况或--usage 打印所有awk选项和每个选项的简短说明. -W棉绒或--lint 打印有关无法移植到传统unix平台的结构的警告. -W旧皮棉或--lint旧皮 打印有关无法移植到传统unix平台的结构的警告. -W posix 打开兼容模式. 但是,它具有以下限制,无法识别: \ x,function关键字,func,转义序列,并且当fs是空格时,新行用作字段分隔符;运算符**和** =不能替换^和^ =; fflush无效. -W重新间隔或--re-inerval 允许使用间隔正则表达式,请参阅(grep中的Posix字符类),例如方括号表达式[[: alpha: ]]. -W源程序文本或--source程序文本 使用program-text作为源代码,可以将其与-f命令混合使用. -W版本或--version 打印错误报告信息的版本. awk脚本由模式和操作组成: 模式{action},例如$ awk'/ root /'测试或$ awk'$ 3 <> 两者都是可选的. 如果没有模式,则该操作将应用于所有记录. 如果不执行任何操作,则输出匹配所有记录. 默认情况下,每条输入行都是一条记录,但是用户可以指定不同的分隔符以用RS变量进行分隔. 该模式可以是以下任意一种: 该操作由一个或多个命令,函数和表达式组成,用换行符或分号隔开,并位于花括号内. 主要包括四个部分: Table1.awk环境变量 变量描述 $ n 当前记录的第n个字段,以FS分隔. $ 0 完成输入记录. ARGC 命令行参数数. ARGIND 当前文件在命令行上的位置(从0开始计数). ARGV 包含命令行参数的数组. CONVFMT 数字转换格式(默认为%.6g) ENVIRON 环境变量的关联数组. ERRNO 最后一次系统错误的描述. FIELDWIDTHS 字段宽度列表(用空格键分隔). 文件名 当前文件名. FNR 与NR相同,但相对于当前文件. FS 字段分隔符(默认为任何空格). IGNORECASE 如果为true,则无论大小写匹配都会被忽略. NF 当前记录中的字段数. NR 当前记录号.
OFMT 数字输出格式(默认为%.6g). OFS 输出字段分隔符(默认为空格). ORS 输出记录分隔符(默认为换行符). 长度 由match函数匹配的字符串的长度. RS 记录分隔符(默认为换行符). RSTART 匹配功能匹配的字符串的第一个位置. SUBSEP 数组下标分隔符(默认为\ 034). 表2. 运营商 操作员说明 = + =-= * = / =%= ^ = ** = 分配 C条件表达式 || 逻辑或 && 逻辑与 ??! 匹配正则表达式和不匹配正则表达式 <=>> =!= ==
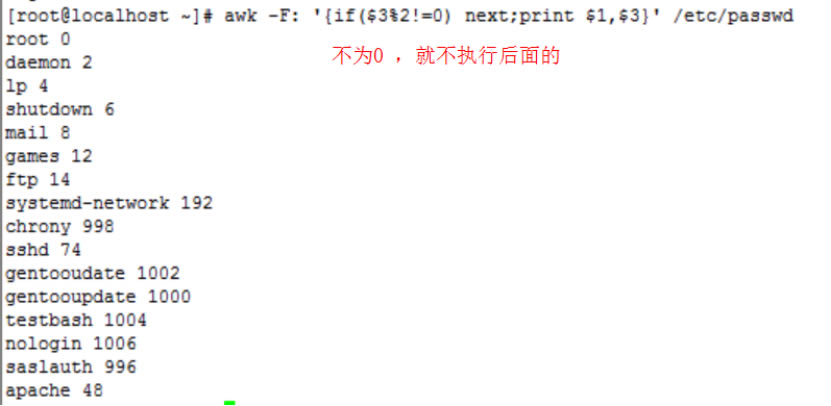
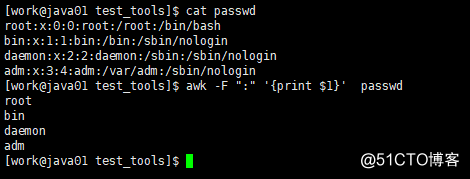
关系运算符 空格 连接 +- 加减 * /& 乘法,除法和余数 +-! 一元加法,减法和逻辑求反 ^ *** 扩展电源 ++- 增加或减少前缀或后缀 $ 字段参考 在 数组成员 awk引用以换行符结尾的每一行作为记录. 记录分隔符: 默认的输入和输出分隔符均为回车符,它们保存在内置变量ORS和RS中. $ 0变量: 它引用整个记录. 例如,$ awk'{print $ 0}'测试将在测试文件中输出所有记录. 变量NR: 计数器. 处理每个记录后,NR的值增加1. 例如awk数组长度,$ awk'{print NR,$ 0}'测试将输出测试文件中的所有记录,并在记录前显示记录号. 记录中的每个单词都称为“域”,默认情况下用空格或制表符分隔. Awk可以跟踪域的数量,并将其值保存在内置变量NF中. 例如,$ awk'{print $ 1,$ 3}'测试将打印测试文件中用空格分隔的第一和第三列(字段). 内置变量FS保存输入字段分隔符的值. 默认值为空格或制表符. 我们可以通过-F命令行选项修改FS的值. 例如,$ awk -F: '{print $ 1,$ 5}'测试将打印由冒号分隔的第一和第五列的内容. 可以同时使用多个域分隔符. 在这种情况下,分隔符应写在方括号中,例如$ awk -F'[: \ t]''{print $ 1,$ 3}'测试,这意味着将space,冒号和制表符作为分隔符. 默认情况下,输出字段的分隔符为空格,并存储在OFS中. 例如,在$ awk -F: '{print $ 1,$ 5}'测试中,$ 1和$ 5之间的逗号是OFS值.
以下内容专用于gawk,不适用于unix版本的awk. \ Y 在单词的开头或结尾匹配一个空字符串. \ B 匹配单词中的空字符串. \ 在单词开头匹配一个空字符串,然后开始定位. \> 在单词的末尾匹配一个空字符串,并在末尾定位. \ w 匹配字母数字单词. \ W 匹配一个非字母数字的单词. \’ 在字符串的开头匹配一个空字符串. \' 在字符串末尾匹配一个空字符串. 用于匹配记录或域中的正则表达式. 例如,$ awk'$ 1?/ ^ root /'test将在测试文件的第一列中显示以root开头的行. 条件表达式1? expression2: expression3,例如: $ awk'{max = {$ 1> $ 3}? $ 1: $ 3: print max}测试. 如果第一个字段大于第三个字段,则将$ 1分配给max,否则将$ 3分配给max. $ awk'$ 1 + $ 2 <100'测试.> $ awk'$ 1> 5 && $ 2 <> 范围模板匹配从第一个模板的第一次出现到第二个模板的第一次出现的所有行. 如果没有出现模板,则它与开头或结尾匹配. 例如,$ awk'/ root /,/ mysql /'test将显示在root第一次出现和mysql第一次出现之间的所有行. $ cat / etc / passwd | awk -F: '\ NF!= 7 {\ printf(“第%d行,没有7个字段: %s \ n”,NR,$ 0)} \ $ 1!?/ [A-Za-z0-9] / {printf(“行%d,非字母和数字用户ID: %d: %s \ n,NR,$ 0)} \ $ 2 ==” *“ {printf(”第%d行,没有密码: %s \ n“,NR,$ 0)}' cat将结果输出到awk,awk将域之间的分隔符设置为冒号. 如果域数(NF)不等于7,请执行以下步骤. printf打印字符串“第??行没有7个字段”并显示记录. 如果第一个字段不包含任何字母和数字,则printf打印“无字母和数字用户ID”,并显示记录和记录的数量. 如果第二个字段是星号,则打印字符串“ no passwd”,后跟记录数和记录本身. BEGIN模块后面是一个动作块,该动作块在awk处理任何输入文件之前执行. 因此无需任何输入即可对其进行测试. 通常用于更改内置变量(例如OFS,RS和FS)的值,以及打印标题. 例如: $ awk'BEGIN {FS =“: ”; OFS =“ \ t”; ORS =“ \ n \ n”} {打印$ 1,$ 2,$ 3}测试. 上面的表达式表示在处理输入文件之前,将字段分隔符(FS)设置为冒号,将输出文件分隔符(OFS)设置为制表符,并将输出记录分隔符(ORS)设置为两个换行符. $ awk'BEGIN {print“ TITLE TEST”}}仅打印标题. END与任何输入文件都不匹配,但是执行动作块中的所有动作,它在处理完整个输入文件后执行. 例如,$ awk'END {print“记录数为” NR}“测试,上面的公式将打印所有已处理记录的数. awk中的条件语句是从C语言借来的,可以控制程序的流程. 14.5.1.if语句
格式:
{if (expression){
statement; statement; ...
}
}
$ awk'{if($ 1 <$ 2)print="" $="" 2“="" too="" high”}'测试.=""> $ awk'{if($ 1 <$ 2){count="" ++;打印“确定”}}'测试.=""> 14.5.2.if / else语句,用于双重判断
格式:
{if (expression){
statement; statement; ...
}
else{
statement; statement; ...
}
}
$ awk'{if($ 1> 100)print $ 1“ bad”;否则打印“确定”}'测试. 如果$ 1大于100,则打印$ 1错误,否则打印确定. $ awk'{if($ 1> 100){count ++;打印$ 1} else {count--;打印$ 2}”测试. 如果$ 1大于100,则将count加1,然后打印$ 1,否则将count加1,然后打印$ 1. 14.5.3.if / else else if语句,用于多个判断.
格式:
{if (expression){
statement; statement; ...
}
else if (expression){
statement; statement; ...
}
else if (expression){
statement; statement; ...
}
else {
statement; statement; ...
}
}
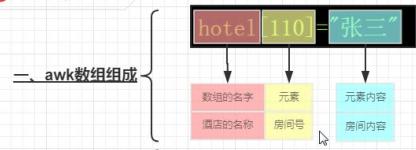
awk中数组的下标可以是数字和字母,称为关联数组. 14.7.1. 下标和关联数组 14.8.1. 字符串函数 14.8.2. 时间功能 14.8.3. 内置数学函数 表4. 函数名称返回值
atan2(x,y) 在y,x范围内的余切 cos(x) 余弦函数 exp(x) 扩展电源 int(x) 圆形 log(x) 自然对数 rand() 随机数 sin(x) 正弦 sqrt(x) 平方根 品牌(x) x是rand()函数的 int(x) 舍入,没有舍入 rand() 生成一个大于或等于0且小于1的随机数 14.8.4. 自定义功能 您还可以在awk中自定义函数,格式如下:
function name ( parameter, parameter, parameter, ... ) {
statements
return expression # the return statement and expression are optional
}
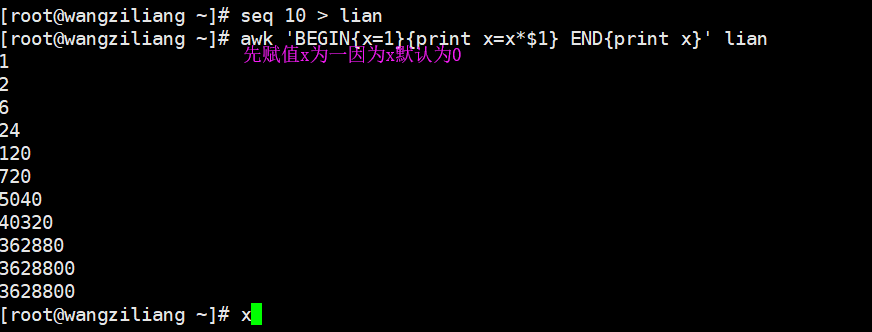
通常,当awk中有多个输入文件时,NR == FNR是有意义的. 如果该值为true,则表示第一个文件仍在处理中. NR == FNR通常用于读取两个或多个文件,并用于判断是否正在读取第一个文件. test.txt 10行内容 test2.txt 4行内容 awk'{print NR,FNR}'test.txt test2.txt 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 11 1 12 2 13 3 14 4 现在有两种文件格式,如下所示: #cat帐户 张三| 000001 李思| 000002 #cat cdr 000001 | 10 000001 | 20
000002 | 30 000002 | 15 所需的结果是在同一行上打印用户名,帐号和金额,如下所示: 张三| 000001 | 10 张三| 000001 | 20 李思| 000002 | 30 李思| 000002 | 15 执行以下代码 #awk -F \ |'NR == FNR {a [$ 2] = $ 0; next} {打印a [$ 1]“ |” $ 2}'帐户cdr 评论: 当NR = FNR为true时,判断当前正在读取第一个文件帐户,然后使用{a [$ 2] = $ 0; next}循环将帐户文件的每一行存储到数组a中,并使用$ 2的第二个字段作为下标引用. 当NR = FNR为false时,判断当前正在读取第二个文件cdr,然后跳过{a [$ 2] = $ 0; next},无条件执行{打印第二个文件cdr a [的每一行] $ 1]“ ||” $ 2},这时变量$ 1是第二个文件的第一个字段,并且在读取第一个文件时,第一个文件$ 2的第二个字段用作数组下标. 因此,您可以在此处使用[[1]]来引用该数组. awk'{gsub(/ \ $ /,“”); gsub(/,/,“”); 如果($ 1> = 0.1 && $ 1 <0.2)c1 +=""> 否则($ 1> = 0.2 && $ 1 <0.3)c2 +=""> 否则($ 1> = 0.3 && $ 1 <0.4)c3 +=""> 否则($ 1> = 0.4 && $ 1 <0.5) +=""> 否则($ 1> = 0.5 && $ 1 <0.6)c5 +=""> 否则($ 1> = 0.6 && $ 1 <0.7)c6 +=""> 否则($ 1> = 0.7 && $ 1 <0.8)c7 +=""> 否则($ 1> = 0.8 && $ 1 <0.9)c8 +=""> 否则($ 1> = 0.9)c9 + = 1; else c10 + = 1; } END {printf“%d \ t%d \ t%d \ t%d \ t%d \ t%d \ t%d \ t%d \ t%d \ t%d \ t”,c1 ,c2,c3,,c5,c6,c7,c8,c9,c10}'/ NEW 示例/示例: awk'{if($ 0?/^>.*$/){tmp = $ 0; getline; if(length($ 0)> = 200){print tmp“ \ n” $ 0;}}}'文件名 awk'{if($ 0?/^>.*$/){IGNORECASE = 1; if($ 0?/ PREDICTED /){getline;} else {打印$ 0; getline;打印$ 0;}}}'文件名 awk'{if($ 0?/^>.*$/){IGNORECASE = 1; if($ 0?/ mRNA /){打印$ 0; getline;打印$ 0;} else {getline;}}}'文件名 awk'{temp = $ 0; getline; if($ 0?/ unavailable /){;} else {print temp“ \ n” $ 0;}}'文件名 substr($ 4,20)--->表示它从第4个字段中的第20个字符开始,一直持续到设置的分隔符“,”结束. substr($ 3,12,8)--->表示它从第三个字段中的第12个字符开始,以截获的8个字符结束. 一个awk字符串到数字 $ awk'BEGIN {a =“ 100”; b =“ 10test10”; print(a + b + 0);}' 110 您只需要通过“ +”操作连接变量. 自动将字符串强制为整数. 非数字变为0,找到第一个非数字字符,以后将自动忽略它. 两个,awk数字将转换为字符串 $ awk'BEGIN {a = 100; b = 100; c =(a“” b);打印c}' 100100 只需将变量与“”符号连接即可进行计算. 三awk数组长度,awk字符串串联操作(字符串串联;链接;串联) $ awk'BEGIN {a =“ a”; b =“ b”; c =(a“” b);打印c}' ab $ awk'BEGIN {a =“ a”; b =“ b”; c =(a + b); print c}' 连接文件中的行: awk'BEGIN {xxxx =“”;} {xxxx =(xxxx“” $ 0);} END {print xxxx}'temp.txt awk'BEGIN {xxxx =“”;} {xxxx =(xxxx“ \”,\“” $ 0);} END {print xxxx}'temp.txt 提取符合条件的子字符串: cat>临时 74938 A> G 347589B> 3795743 awk'{x = $ 0; while(match(x,“ [AZ]> [AZ]”])> 0){print substr(x,RSTART,RLENGTH); x = substr(x,RSTART + RLENGTH);}}'temp awk字符串函数,包括用法示例:
|
温馨提示:喜欢本站的话,请收藏一下本站!
本站发布的Win7纯净版系统、Win10纯净版和XP纯净版系统仅为个人学习测试使用,请在下载后24小时内删除,不得用于任何商业用途,否则后果自负,请支持购买微软正版软件!
本站所有资源全部来自于网络资源,如侵犯到您的权益,请及时通知我们(),我们会及时处理.
Copyright © 2018-2020 萝卜系统 手机站 关于本站