|
根据运行的环境,操作系统可以分为桌面操作系统,手机操作系统,服务器操作系统,嵌入式操作系统等。
正则表达式测试平台: 最近,我正在为Lazada卖方中心进行自我注册项目. 店铺名称验证规则更加复杂. 要求是: 1. 英文字母大小写 2. 数字 3. 越南语 4. 一些特殊字符,例如“&”,“-”,“ _”等. 当我看到这个要求时,我自然想到了正则表达式. 因此,有以下表达式(以比较形式编写): ^([A-Za-z0-9 ._()&'\-] | [aAàà???áá????????????????a??????????bBcCdD??eEèè????éé??ê??êfê??????????FFgGhHiIìì????íí??jJkKlLmMnNoOòò????óó???????????????????????????pPQQrRsStTuTu] 在测试环境中,此表达式在功能上满足了业务方的要求,并已发布到马来西亚的环境中. 结果联机后,发现联机计算机的CPU飙升至100%,这导致整个站点的响应速度异常缓慢. 通过转储线程跟踪,发现所有线程都卡在此正则表达式的验证中:
一开始令人难以置信,正则表达式匹配过程如何导致CPU变高?我以怀疑的态度搜索了数据,发现小的正则表达式中有很多文章. 它们通常以轻松的方式编写. 只要他们能够满足功能要求,他们就会认为自己已经实现了目标,并且完全忽略了可能带来的后果. 隐藏的性能. 正是造成这种流血罪行的所谓常规“灾难性回溯”. 下面将详细描述此问题,以避免重复相同的错误.
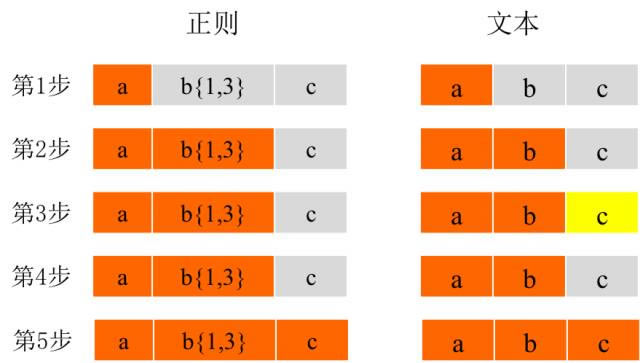
说到回溯陷阱,让我们从正则表达式引擎开始. 常规引擎可以分为两个基本类别: 一类是DFA(确定性有限自动机),另一类是NFA(不确定的有限自动机). 简而言之,NFA对应于以正则表达式为主导的匹配,而DFA对应于以文本为主导的匹配. DFA从匹配的文本开始,从左到右,每个字符将不匹配两次,其时间复杂度是多项式,因此通常更快,但是支持的功能很少,不支持捕获组,各种引用,等等. ; NFA从正则表达式开始,并连续读取字符以尝试匹配当前的正则性,并吐出字符以在不匹配时重试. 通常情况下,速度较慢且时间最佳. 复杂度是多项式,最坏的情况是指数. 但是NFA支持更,因此在大多数编程方案(包括Java,js)中,我们都面临NFA. 以下面的表达式和文字为例, text =“今晚之后” regex =“ to(nite | nighta | night)” 当NFA匹配时,根据正则表达式匹配文本. 从t匹配a,失败,继续直到文本中的第一个t,然后将o和e比较,失败,常规回退到t,继续直到文本中的第二个t,然后文本中的o和o也匹配,继续,正则表达式后面有三个可选条件,依次匹配,第一个失败,然后两个java正则表达式详解,三个直到匹配. 匹配DFA时,文本用于匹配正则表达式,从a到t匹配,直到第一个t匹配正则t,但是e不能匹配o,继续直到文本第二个t其中匹配常规t,然后o匹配o. 当n发现常规中存在三个可选匹配项时,它开始并行匹配,直到文本中的g使第一个可选条件不匹配为止,继续,直到最后一个匹配项. 如您所见,在DFA匹配过程中,文本中的字符仅被比较了一次. 不吐出的操作应比NFA快. 另外,无论正则表达式如何编写,对于DFA,文本匹配过程都是一致的,并且文本的字符从左到右依次匹配,因此DFA在匹配过程中与正则表达式无关,而且NFA对于不同的正则表达式具有相同的作用,匹配过程完全不同. 在讨论引擎之后,让我们看看什么是回溯. 对于以下表达,我相信每个人都非常清楚其意图, ab {1,3} c 也就是说,中间的b需要匹配1?3次. 因此,对于文本“ abbbc”,根据第1部分中NFA引擎的匹配规则,不会发生回溯. 表达式中的a匹配后,b恰好完全匹配文本中的3 b,然后c匹配,一次全部匹配. 如果我们将文本更改为“ abc”怎么办?它只不过是字母b缺失,而是发生了所谓的回溯. 匹配过程如下所示(橙色是匹配项,是不匹配项),
第1步到第2步应该很容易理解,但是为什么要从第3步开始,尽管与b {1,3}匹配的文本中已经有ab了,但是字母c和b {1,3会被拖到后面}比较呢?这是我们将在下面提到的常规贪婪功能,这意味着b {1,3}将尽最大可能匹配最多的字符. 在这个地方,我们首先知道它必须匹配,直到撞到南墙为止. 在这种情况下,步骤3中的不匹配之后,整个匹配过程没有完成,但是字符c像堆栈一样被吐出,然后使用正则表达式中的c来处理文本中的c. 比赛. 这发生了回溯. 让我们看看什么是贪婪模式.
我相信每个人都知道如何使用以下特殊字符: i. ?: 告诉引擎匹配领先字符0次或一次. 实际上,这意味着开头字符是可选的. ii. +: 告诉引擎一次或多次匹配前导字符. iii. *: 告诉引擎匹配开头字符0次或多次. iv. {min,max}: 告诉引擎从最小到最大时间匹配前导字符. min和max均为非负整数. 如果有逗号并且省略了max,则表示max没有限制. 如果同时省略了逗号和max,则表示重复了min次. 默认情况下,这些特殊字符是贪婪的,也就是说,它们将根据前导字符匹配尽可能多的内容. 这解释了为什么在第3部分的示例中,步骤3之后发生了事情. 在上述字符后添加问号(?)以启用惰性模式. 在这种模式下,常规引擎将重复尽可能少的匹配字符. 匹配成功后,它将继续匹配其余字符串. 在上面的示例中,如果将正则表达式更改为 ? ab {1,3}?c 匹配过程如下(橙色匹配,不匹配)
可以看出,在非贪婪模式下,在b {1,3}之后?步骤2中的b与文本b匹配,然后使用c匹配文本中的c而不回溯.
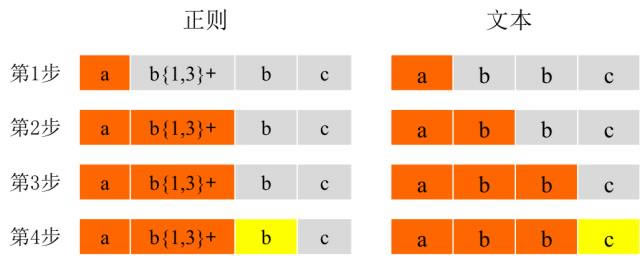
如果在上述四个表达式之后添加加号(+),则独占模式将打开. 像贪婪模式一样java正则表达式详解,独占模式将匹配最长的模式. 但是,在独占模式下,正则表达式尽可能匹配字符串. 一旦比赛失败,它将结束比赛而不会返回. 让我们以下面的表达式为例, ? ab {1,3} + bc 如果我们使用文本“ abbc”来匹配上述表达式,则匹配过程如下所示(橙色是匹配项,是不匹配项),
可以发现,在第2步和第3步中,b {1,3} +与文本中的两个字母b匹配,而结果文本中仅保留一个字母c. 然后在第四步中,常规文本中的b与文本中的c匹配. 如果无法匹配,则不执行回溯. 此时,整个文本无法与正则表达式匹配. 如果删除了正则表达式中的加号(+),则整个文本匹配. 列出以下三种模式的表达式,如下所示: 贪婪 懒惰 独家 X * X * +
X + X ++ X {n} X {n}? X {n} + X {n,} X {n,}? X {n,} + X {n,m} X {n,m}? X {n,m} + 现在回顾一下本文开头的很长的正则表达式,实际上,经过简化后,它就像一个表格
表达 . 字符集大小约为250,+号表示该字符集至少出现一次. 根据上述NFA引擎的贪婪模式,当用户输入一个过长的字符串以进行匹配时,一旦发生回溯,计算量将很大. 后来,采用了独占模式,也解决了100%CPU问题.
|
温馨提示:喜欢本站的话,请收藏一下本站!
本站发布的Win7纯净版系统、Win10纯净版和XP纯净版系统仅为个人学习测试使用,请在下载后24小时内删除,不得用于任何商业用途,否则后果自负,请支持购买微软正版软件!
本站所有资源全部来自于网络资源,如侵犯到您的权益,请及时通知我们(),我们会及时处理.
Copyright © 2018-2020 萝卜系统 手机站 关于本站