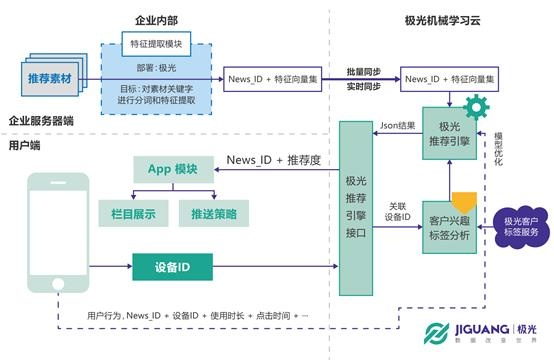
|
�������еĻ���������ϵͳ���Է�Ϊ�������ϵͳ���ֻ�����ϵͳ������������ϵͳ��Ƕ��ʽ����ϵͳ�ȡ�
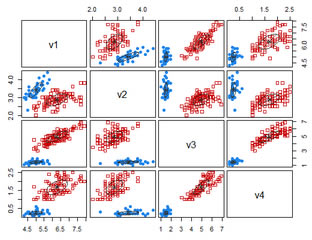
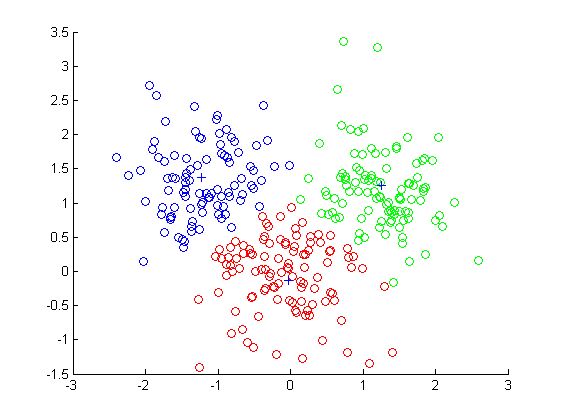
��Ⱥ������CA����һ�ֵ��͵��ලѧϰ����. �˷������ݶ���������������Ϊ��ͬ����. ��һ��������Ϊ���ƶ���Ĺ��̳�Ϊ����. ��. Ⱥ����ͬһȺ���б˴����Ƶ�������Ⱥ���еĶ������Ƶ����ݶ���ļ���. һ�����ݶ��������Ϊһ�飬��˾����Ҳ������Ϊһ������ѹ����ʽ. ���ܷ��������ֶ������������Ч�ֶΣ�������ͨ����Ҫ������ռ��ͱ�Ǵ���ѵ��Ԫ���ģʽ�����ҷ�����ʹ����ЩԪ���ģʽ��ÿ������н�ģ. ��Ϊһ���ල��ѧϰ�������������ⷽ����Ȼ������. ��Ⱥ������һ����Ҫ������. �ڶ�ͯ���ڣ�����ѧϰ�������è����ֲ������ϸĽ�DZ��ʶ�����. ͨ���Զ����࣬���ǿ���ʶ�����ռ��е��ܼ������ϡ�����Ӷ���������ֲ�ģʽ����������֮����Ȥ�Ĺ���. ��������ѹ㷺Ӧ��������Ӧ���������г��о���ģʽʶ�����ݷ�����ͼ����. ��ҵ���У���Ⱥ������Ӫ����Ա������ͻ����еIJ�ͬ�飬�����ݹ���ģʽ�������ͻ���. ������ѧ�У������������Ƶ�����ֲ���������Ծ������ƹ��ܵĻ�����з��࣬�������˽���Ⱥ���ڲ��ṹ. ��Ⱥ���������ڵ���۲���ʶ�����Ƶ�����ʹ�������ݷ������ͣ���ֵ�͵���λ��ȷ�������е�ס����𣬲�Ϊ�������ռ��ű���������ȷ�����ߵ�ƽ������ɱ�. ��Ҳ�������ڰ���������Ϣ���ֺ�Web�ϵ��ĵ�����. ��ijЩӦ�ó����У�����Ҳ��Ϊ���ݷֶΣ���Ϊ�����������ݴ������ݼ��������Խ����Ϊ����. ����Ҳ����������Ⱥֵ���. ��Ⱥֵ����Ӧ�ð��������թ�ͼ��ӵ��������еĻ. ���磬�����е��쳣���������dz������Ƶ������������թ��ı�־. ��Ϊ�����ھ��ܣ�����������������������ߣ��������˽����ݷֲ����۲�ÿ���������������רע���ض��ľ��༯�Խ��н�һ������. ���ߣ����������������㷨��Ԥ�������裬��������������Ӽ�ѡ��ͷ��࣬Ȼ�Լ��ľ����ѡ�������Ի��������в���. K��ֵ��ʹ����㷺�ľ����. ������������k-Medoid���ֲ�����DBSCAN. �������EM��Ҳ�����ھ�������Ľ������. �������������������Ӧ�ã����������ھ��г��о�����Ⱥֵ���. ���⣬��ά����Ҳ��һ�������ھ���������ලѧϰ����������ʹ��������ɷַ�����PCA���������б������Isomap. [������Դ: Han J .������M.�Ὠ��2011��. �����ھ�: ����ͼ���. Ħ����������. ] ���ھ�������������о���ʼ��60��ǰ-K-means�㷨�ij��֣����㷨��Steinhaus��1955���״������Ȼ��Stuart Lloyd��1957�������K-means�����㷨. �Ƽ�ϵͳ��ʹ�õļ���. �û����Է�Ϊ��ͬ�����Ի��������ԵĽ���. ��ˣ����������ΪӦ�ý�. 1978�꣬David Harrison��Daniel L Rubinfeldʹ��K-means�����㷨�о����ز��г�����. ����ʹ�÷��ز��г�������������������������Ը. 1987�꣬Kaufman��Rousseeuw�����Χ��Medoids������з����ķ������÷���������������Ϥ����������㷨�Ļ���. 1992�꣬Vladimir Batagelj��Anu?kaFerligoj��Patrick Doreian������һ�ָĽ����ض�λ�㷨��һ�ָĽ��ľۼ�����㷨. ��1996�꣬Martin Ester��Hans-Peter Kriegel��J?rgSander��Xuxiaowei�����ʹ������/ DBSCAN�Ļ����ܶȵ�Ӧ�ó���ռ����. ���㷨�����ܶ�: �����ռ��е�һ��㣬���㷨���Խ������ĵ��Ϊһ�飨�����������ڵ�ĵ㣩������dz�λ�ڵ��ܶ������еĵ�DBSCAN����õľ�������㷨֮һ��Ҳ��������õĿ�ѧ����֮һ����Ծ��������������Զ��Ӱ��. 2014����ά������������㷨�������ھ����KDD�ϱ����衰ʱ����ԡ������ý�����������ۺ�ʵ��ˮƽ��һֱ�ܵ���ע��ijЩ�㷨. ͬ����ά���������������ʹ�ò�νṹ��ƽ��������ٺ;��ࣨBIRCH������. BIRCH��ʹ�ò�νṹ����ƽ��ĵ���Լ��;��ࣩ��һ���ල�������ھ��㷨�����ڶ��ر������ݼ�ִ�зֲ����. BIRCH��һ���ŵ��ǣ������Ե����غͶ�̬�ؾۺ�����Ķ�ά�������ݵ㣬�Ա�Ϊ��������Դ�����ڴ��ʱ�����ƣ��������������Ⱥ��. �ڴ��������£�BIRCHֻ��Ҫɨ��һ��. ���ķ���������BIRCH�ǡ�����������ĵ�һ����Ч�����������������ݵ㲻�ǻ���ģʽ��һ���֣��ľ����㷨��������ģ�����ܷ��������DBSCAN. ���㷨��2006���Ƴ����ٻ�SIGMOD10����Խ�.
���ھ���������о��Ѿ��൱���죬Ŀǰ�����ھ����㷨�Ĺ�ҵӦ����. ���磬��2005��������Netflixʹ��DBSCAN�������쳣�ٶȱ��������������ö���쳣������. 2011�꣬Roman Filipovych����ѧ�������˾�����������ԵĽ���״�������������������ڷ�������MRͼ���������ľ����������. ʹ��IEEE����ʱ�����Ƿ�����1500������������йصĽ�������ǣ�����������ܵ��ع������ע��һ�룬��˸�ģ�Ϳ��ܱȹ��ڵĸ�֪���뻹С. ��� �¼� �������/�ο����� 1955 Steinhaus�����K-means�㷨��ԭ�� Steinhaus��H.��1956��. �μ����������. Bull.acad.polon.sci.cl.iii��801-804.
1957 Stuart Lloyd���ȿ�����K-means�㷨��Ҳ��ΪLloyd�㷨�� �Ͱ��£�Lloyd��S.P.����1982��. PCM�е���С����������IEEE��Ϣ����ѧ����28��2��: 129�C137. 1978 Harrison D.��Rubinfeld D.L.��K-means�����㷨�о����ز��г����� Harrison��D .�� Rubinfeld��D.L.��1978�������������ס���۸�Ͷ����������������������������. 5��1��: 81-102. 1987 Kaufman��Rousseeuw�����Χ����̴�����ķ�����Χ����̴�����ķ�����
Kaufman��L .�� Rousseeuw��P .�� ��1987��. ������̴����о���. ����L1��������ط�����ͳ�����ݷ���. 405-416ҳ. 1992 Vladimir Batagelj��Anu?kaFerligoj��Patrick Doreian������һ�ָĽ����ض�λ�㷨��һ�ָĽ��ľۼ�����㷨 Batagelj��V .; A. Ferligoj�� Doreian��P.��1992�꣩�����ṹ�Եȵ�ֱ�Ӻͼ�ӷ����������罻���硷. 14��1-2��: 63-90. 1996 Martin Ester��Hans-Peter Kriegel��J?rgSander��Xuxiaowei����˻����ܶȵ�Ӧ������/ DBSCAN��Ӧ�ó���ռ���� Ester��M.; Kriegel��H.-P .;ɣ�£�J. Xu��X.��1996��. һ�ֻ����ܶȵ��㷨�������ڴ��������Ĵ��Ϳռ��з��־���. �ڶ���֪ʶ���ֺ������ھ���ʻ������ļ���KDD-96��. 1996
������ʹ�ò��/ BIRCH�����ľ������Լ��;��� Zhang��T .;��������ϣ�ϣ�Ramakrishnan��R.�� Livny��M. ��1996��. BIRCH: һ�����ڴ��͵���Ч���ݾ����. 1996��ACM SIGMOD�������ݹ�����ᣨ96������Ļ���¼. pp. 103�C114. 2011 ������������ά�棨Roman Filipovych����ѧ�����þ�����������ԵĽ���״�� Filipovych��R .; Resnick��S.M .�� Davatzikos��C.��2011�꣩. Ӱ�����ݵİ�ල�������. NeuroImage. 54��3��: 2185-2197. ������һ��������ս���о�����. �����Ǿ���������ٵ�һЩ������ս: ����չ��: ��������㷨�����ڰ������ڼ��ٸ����ݶ����С�����ݼ�. ���ǣ����Ϳ��ܰ��������������. ��������������ܵ���ģ������K��ֵ����Ӱ�죬��ʱ�����Ǻܿɿ�. �ض��������ݼ�������������ܻᵼ�½����ƫ����������Ҫ�߶ȿ���չ�ľ����㷨. ������ͬ���͵����Ե�����: �����㷨ּ�ڶԻ��ڼ���ģ����֣����ݽ��о���. ���ǣ�Ӧ�ó��������ҪͬʱȺ���������͵����ݣ���������ƣ����ࣨ��ƣ����������ݣ�������Щ�������͵Ļ��. ������ij��������������㷨�����־���������״�ľ��ࣩ: ��������㷨���ǻ���ŷ����þ��������Manhattan���������ȷ�������. �������־���������㷨�������ҵ���С���ܶ����Ƶ����δ�. ���ǣ��ؿ������κ���״. �������Լ��������״�Ĵص��㷨�dz���Ҫ. ǿ��ij�����ֵ��ȷ���������������֪ʶ�����Ҫ��: ��������㷨Ҫ���û��ھ������������ijЩ����������������ľ�������. ���������ܶ���������dz����У���ȡ���ڷ�����Ա������ȷ��ѡ���Ҿ�������Ľ���������ܲ���Ψһ��. ���ǣ���Щ��������ʵ�������ͨ������ȷ���������Ƕ��ڰ�����ά��������ݼ�. �ⲻ�����û���������������ʹȺ�����������Կ���. ���⣬��DBSCAN�У�������ݼ����ܶȲ�һ�£������ȷ���ŵ�ѡ��. �����������ݵ�����: �������ʵ��������쳣ֵ��ʧ��δ֪����������. һЩ�����㷨����Щ�������У������ܵ��������ϲ�ľ�����. ��������Ͷ������¼��˳������: һЩ�����㷨�����²�������ݣ������£��ϲ������еľ���ṹ��. �෴�������ͷ��ʼȷ��һ���µľ���. ���������㷨���������ݵ�˳������. ���仰˵������һ�����ݶ��������㷨���Ը����������ı�ʾ˳�����Բ�ͬ�ľ���. �������������㷨�Ͷ�����˳�����е��㷨�dz���Ҫ. ��ά��: ���������ά�Ȼ�����. ��������㷨�ó�������ά���ݣ����漰��ά����ά. ���۷dz��ó��ж϶������ά�ȵľ�������. �ڸ�ά�ռ��в������ݶ����Ⱥ���dz�������ս�ԣ������ǿ��ǵ���Щ���ݿ���ϡ���Ҹ߶�ƫб. ����Լ����Ⱥ��: ʵ��Ӧ�ó��������Ҫ�ڸ���Լ����ִ��Ⱥ��. �������Ĺ������ڳ�����ѡ��������������Զ����л���ATM����λ��. Ҫ���������ľ����������Կ��dz��к�����·����Լ���������Լ�ÿ����Ⱥ�пͻ������ͺ��������Լ�ͥ���з���. �ҵ�����ָ��Լ���������������ܵľ������dz�������ս��. �ɽ����ԺͿ�����: �û������������ǿɽ��͵ģ�������ĺͿ��õ�. ���仰˵��������Ҫ��������ض���������ͺ�Ӧ��. �о�Ӧ��Ŀ�����Ӱ�켯Ⱥ���ܺͷ�����ѡ�����Ҫ. ���⣬�������Ͻ����������ʼ�ռ�����ڷ��飬�������ּ�����������Ļ�����. �ڽ�����Ӧ���У������������������һ��������. �ƺ�������ʹ�á���Ⱥ�����������ٴ���ʹ����������ӿɿ����ȶ����������ڸ�����ҵ��Ӧ��. ����: �����£���Ī˹
|
��ܰ��ʾ��ϲ����վ�Ļ������ղ�һ�±�վ��
��վ������Win7������ϵͳ��Win10�������XP������ϵͳ��Ϊ����ѧϰ����ʹ�ã��������غ�24Сʱ��ɾ�������������κ���ҵ��;���������Ը�����֧�ֹ���������������
��վ������Դȫ��������������Դ,���ַ�������Ȩ��,�뼰ʱ֪ͨ����(),���ǻἰʱ����.
Copyright © 2018-2020 �ܲ�ϵͳ �ֻ�վ ���ڱ�վ