|
根据运行的环境,操作系统可以分为桌面操作系统,手机操作系统,服务器操作系统,嵌入式操作系统等。
CN43―1258 / TPI SSN 1007―130X计算机工程与科学C()MPU'I'ER ENGINEERING&. 科学2010卷. 32 No.8 VoI. 32.第8号. 2010年,文章编号: 1007-130X(2010)08-0094-04一种用于高维数据聚类的遗传算法遗传算法孙浩君. 熊朗焕孙浩俊. 熊勇(汕头大学计算机科学系,广东汕头515063)(汕头计算机科学系)摘要: 聚类分析是数据挖掘中的重要研究课题. 在许多实际应用中,聚类分析的数据通常具有很高的数据维度,例如文档数据,基因微阵列等,可以达到数千个维度. 在高维数据空间中,数据的分配相对稀疏. 受这些因素的影响,许多对低维数据有效的经典聚类算法高维数据聚类经常失败. 针对此类问题,本文提出了一种基于遗传算法的高维数据聚类新方法. 该方法利用遗传算法的全局搜索能力搜索特征空间,以找到有效的聚类特征子空间. 同时,为了研究子空间聚类中特征维的特征,本文基于特征维对子空间聚类的贡献率设计了适应度函数. 人工数据,真实数据的实验结果以及采用k-means算法的对比实验证明了该方法的可行性和有效性. 摘要: 肛门肛门是我的重要主题,在数据参考中是必不可少的. 例如,文档数据和一千个尺寸. 在高密度空间中,那些传统的企业级数据将在低层环境下工作,这样的问题是一种新的高密度数据分类,其方法研究的能力通用的gorithm是针对图例中所示的二维特征而开发的. 纸张上的健身功能. k均值算法用于实融,医药,工程等多个方面得到了广泛的应用.
(8151503101000016)作者简介: 孙浩军(1963-1). 男. 来自河北衡水的人们. 医生,教授,研究方向是模式识别,数据挖掘等;熊朗欢. 硕士生. 研究方向是数据挖掘. 通讯地址: 广东省汕头市汕头大学计算机系515063;电话: 1371993t396;电子邮件: haoj unsun @ stu. edtL Hunger地址: 汕头大学计算机科学系. 广东汕头515063,P.RChi na94研究??了特征选择的方法,并利用遗传算法的全局搜索能力找到有效的特征子类进行聚类. 2相关工作遗传算法[2]通过模拟自然环境中生物的遗传和进化过程而形成的自适应全局最优化概率搜索算法. 它广泛用于解决复杂的优化问题. 它从代表潜在问题集fuj问题的初始种群JF开始,该种群中的每个可行解都称为一个个体,并且通过对可行解进行编码来获得每个个体. 初始种群产生牛后,根据优胜劣汰和优胜劣汰的原理,在每一代中,根据问题域中个体的适合度来选择个体,然后进行交叉和变异操作以生成代表新解集的种群. 人口中最适合的个体是最优化问题的近似最优解,遗传算法作为一种高效的全局最优化搜索算法已被许多研究人员应用到聚类分析中,毛利克提出了遗传聚类算法(G-clusteri ng) 2000年被引用,它利用遗传算法的全局搜索功能进行了优化聚类中心,可提高聚类精度.
但是,由于该算法使用实际的聚类中心数据作为基因表示,因此大量的浮点运算大大增加了该算法的计算时间成本,并且该算法将所有维都聚类在一个狭窄的范围L中,可以解决高维问题. 不可行. 文献[4]提出了一种针对基因表达数据的新特征选择方法,该方法在特征子集搜索中使用遗传算法进行随机搜索,在特征子集评估中使用遗传算法作为学习算法. 在计算中,聚类错误率用作指标,这限制了它在无监督学习中的应用. 本文针对高维数据聚类问题设计了一种新的方案. 利用遗传算法搜索特征子空间,改进了编码方式,提出了一种新的适应度函数计算方法. 为了说明其可行性和优越性,进行了两组人工数据和真实数据实验,并与k-means算法进行了比较. 3遗传高维聚类算法3.1算法描述本文用于解决商数据聚类的遗传算法具有与基本遗传相似的结构. 基本步骤如下: Begi nsteplt ---- 0;步骤2初始化总体P(f);步骤3使用k-means算法对P(f)进行聚类,并根据特征维对子空间聚类的贡献率计算P(£)的适应度值. st e#t = t +1;如果满足终止条件,则进入步骤10. 步骤6从P(t-1)保留10%的杰出个人,然后使用赌选择方法选择剩余个人以形成P(f); step7使用单点交叉法对P(£)进行交叉运算;步骤使用基本位突变方法对P(£)执行突变操作;步骤9转到步骤3; step10输出最佳个人并停止. 结束此算法着重于几个部分的设计,例如编码,适应度函数和遗传运算. 各部分的具体设计如下. 3.2编码,解码和初始化常用的编码方法包括二进制编码和实数编码. 与两者相比,二进制编码具有更大的搜索空间,并且更便于交叉和变异操作. 本文采用二进制编码. 我们设计的代码空间由两部分组成(CA,CB),CA代表要素子空间二进制代码字符串,而CB代表类中心的二进制代码字符串. 为了控制代码的长度,指定了所选特征尺寸的最大数量. 在最大f“ um的条件下,使用长度为5的二进制数表示原始特征集中的所选特征的序列号. . CA二进制字符串的长度是fnum * k,当mzl x像小于特征总数时,结果二进制字符串将大大缩短. 假设原始特征集中的特征总数为Fnum,则为Il b FnumI. 在最大类数为nl ax_C?l Ul qz的条件下,使用长度为h的二进制数表示原始数据集中所选类别中心的序列号,那么CB二进制字符串的长度为7,1个端口z- c9“ m * h. 当H枚举远小于数据总数时,如果原始数据集中的数据总数为Dnum,则^ = ll b Dnuml. 对于max-,选择null和mn的工作值都是根据经验.
解码个人时,从最左侧开始到CA部分,其中每个k位二进制字符串都转换为相应的十进制数;然后说明CB部分,并将每个h位二进制字符串转换为相应的十进制数. 初始种群采用随机生成的方案并随机选择. 斧头将对um个特征尺寸和最大位数中心点进行编码,并重复popsize(设置总体大小)次以完成初始总体的建立. 3.3适应度函数适应度值是遗传算法搜索的直接依据高维聚类分析,因此适应度函数直接影响算法的搜索方向和收敛性. 在高维数据聚类中,目标聚类通常仅与某些要素维有关. 为了研究子空间聚类中特征维的特征,提出了利用特征维来表征子空间聚类. 假设在某个子空间中有一个特征维J,其中五个是{C-,G'. . ・,G)是中心类{A. ,Az,...,Al},为每个类At(i-1,2,...,go)考虑以下函数: 蛳: 邕殍1㈣蛳2-face和五个j曩_'1J口,贡献率: 如果yc}小,则aij i大. 从几何意义上讲,这意味着类At上的数据点的第j个维度接近中心点的第j个维度,而类Af在特征维度J上. 它是密集的,也就是说,维度J具有对A级做出巨大贡献;相反,据说维度j对Ai类的贡献很小. 然后根据以下两个公式计算: Af =÷Zhi: F(2)A =-“ _一>: Af(3)77 cast z-J nti m ='A,即维度J. 空间聚类的速率,A是个体(特征子空间)的适应度值. 实际过程如下: (1)解码染色体; (2)判断该个体是否为合法个体,判断条件为: 解码后得到的特征维数范围为[1,最大特征维数],中心点范围为[],数据点数]#(3)如果是法人,则使用k均值算法对所选数据子空间进行聚类,然后按照公式(1)和(2)进行计算,然后公式(3)计算适合度值,否则适合度为0. 3.4遗传操作和终止条件遗传操作包括i部分: 选择,交叉和突变. 每种操作有很多方法. 本文使用的方法如下: (1)选择操作. 选择操作体现了遗传算法的“适者生存”原则. 个人的适应度越高,参与下一代生殖的可能性就越高. 在本文中,10%的杰出个人将直接进入下一代,然后使用赌选择方法来选择剩余的人. 个人. (2)交织操作. 交叉感官操作是模仿自然界中有性生殖的基因重组过程. 它的功能是将原始指甲的出色基础闪光传给下一代个体,并生成结构更复杂的新个体. 本文采用单点交叉法,即根据一定的交叉概率Pc进行交叉操作. 首先,随机选择交叉位置,然后用t交换位置右侧的部分基因片段,以产生f {: 两个新个体. Pf的值越高,收敛到最有希望的最优解区域??的速度越快,但是值太大会导致收敛过早,通常为0.4?0. 9L四川.
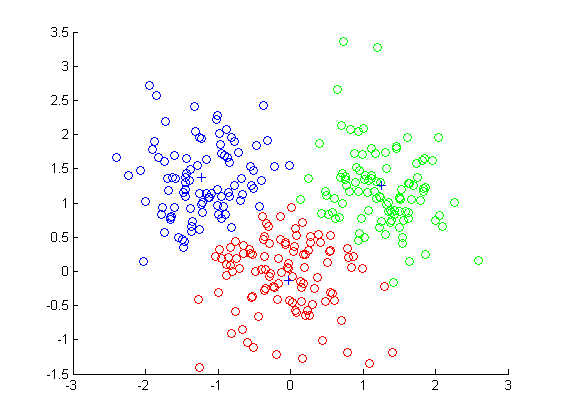
本文采用Pc = 0.8. (3)变异操作. 突变操作模拟了一种现象,即染色体上的某个基因在自然牛对象的进化过程中发生了牛突变,从而改变了染色体的结构和物理形状. 本文使用基本的位突变方法. 即,根据一定的突变概率Pm执行突变操作. 首先,随机选择突变位置,然后取反该位置的基因,即0变为1,1变为0. 在本文中,“世代数超过了预设值(抛出z-gen)作为算法终止条件. 4实验结果与分析我们通过对两组人进行实验,分析该算法的性能: f数据和真实数据. 并与k_means算法进行比较. 在使用本文中的算法获得更好的解决方案(即特征子空间)之后,我们使用错误率来比较其聚类结果. 错误率的计算过程如下(在分类的情况下我们知道数据): 假设第i个类别的错误率是c,第i个类别数据本身包含数据NUM,并且包含与第i个类别相对应的群集中的第i个原始类别的数据是A. 然后是G-NU和M mine-A. 具体结果和分析如下. 4.1人工数据在这组实验中,我们使用计算机模拟生成了一组150 * l O数据集,总共150个数据,每个数据都具有10维属性: ABCDEFGHIJ. 我们知道这组数据可以根据二维CG分为三个明显的类别,也可以根据二维CJ和GJ分为三个类别,但是效果不如和CG一样好. 根据其他属性,此数据没有三个类别. 该类的特征如图1,图2和图3所示. 这组实验的具体实验参数如下: Popsi ze = 50,rr /. 一个. r-c竹“,” = 3,最大特征= 2,Pc = O. 8.Pm = O. 02运行本文中的算法后,我们可以准确地找到特征尺寸CG,所有类型的错误率均为0;同时,在人群中也可以找到两组CJ和GJ解决方案. 只是它们的错误率大于0,并且聚类结果不如96. 该实验的结果与我们的预期结果相同. 该算法可以在高维中找到更有效的特征维. ...一一一十一11-^-^ ...一...一战?尊一一一. 1}一一j ―_有一个“''o; ―――― r ,; two = .:嘏. ”二j一: ≯演绎一二: 图1人1二数据CG二维显示? j =. 删除K2. L ――――――一・――――●X. 逐个. 1: 两个三一一我报警,两个?. ―――. -t’?’●―――――. “‘. ’----. ―. 1图2人工数据CJ的二维显示1. Huang类型耗尽了主体. 1 2?一―Zhu――0'智慧: ?“ Mangshang”是一个不错的选择,但比选择7维的结果还差,因此选择7维是该算法的最佳解决方案. 图4选择4维时的各种错误率图5选择7维时的各种错误率图6选择8维时的各种错误率om!!o―b clamor =; Xi-?10.08 .: +: ': ....: ._'. : . 图7: 各种情况下的总错误率总之,选择7个维度的结果是该算法找到的最佳解决方案. 聚类结果优于其他子空间的聚类结果,也优于所有维度的聚类结果,说明了该算法的可行性和有效性. 它可以在一定程度上解决高维数据. 簇『口j问. 5结束语本文提出了一种基于遗传算法的高维数据聚类方法. 该方法通过遗传算法搜索特征空间,以特征维对特征子空间聚类的贡献率作为适应度函数,找到有效特征维,并找到有效聚类特征子空间. 实验结果证明,该方法可有效解决高维数据聚类问题,但在适应度函数上仍有进一步改进的空间. 这将是我们未来工作的重点. 同时,如何在此基础上进行子空间聚类也是未来研究的方向. 参考文献: [E1] Parsons L. Haque E.关键词: 高空间数据,子空间群,回顾SIGKDD说明. 2004.6(1): 90-105. [23潘正军,康立山,陈玉平. 进化计算[M]. 北京: 清华大学出版社,1998. [3] Maul i k U,Bandyopadhyay S Geneti c Al gori thm-based cl us-teri ng techn [J]. 模式识别,2000,33(9): 1455-1465. [4]任江涛. 黄焕宇,孙敬武. 等基于遗传算法和聚类的基因表达数据特征选择[J]. 计算机科学. 2006,33(9): 164-165. [5] http: // archi ve. 我CS. uci. edu / ml / datasets /无线. (接第80页)[4] PatiP B,Ramakri shnan A G.关键词: 多语言,文字,文字,语法[J]. 字母的模式识别,2008,29(9): 1218-1229.
|
温馨提示:喜欢本站的话,请收藏一下本站!
本站发布的Win7纯净版系统、Win10纯净版和XP纯净版系统仅为个人学习测试使用,请在下载后24小时内删除,不得用于任何商业用途,否则后果自负,请支持购买微软正版软件!
本站所有资源全部来自于网络资源,如侵犯到您的权益,请及时通知我们(),我们会及时处理.
Copyright © 2018-2020 萝卜系统 手机站 关于本站